Traditional OCR is a rule-based technology designed to recognize text by analyzing the physical structure and patterns of pixels in an image.
Think of it as a librarian who recognizes a "B" not because they understand the word "Book," but because they’ve been trained to recognize two loops stacked on a vertical line.
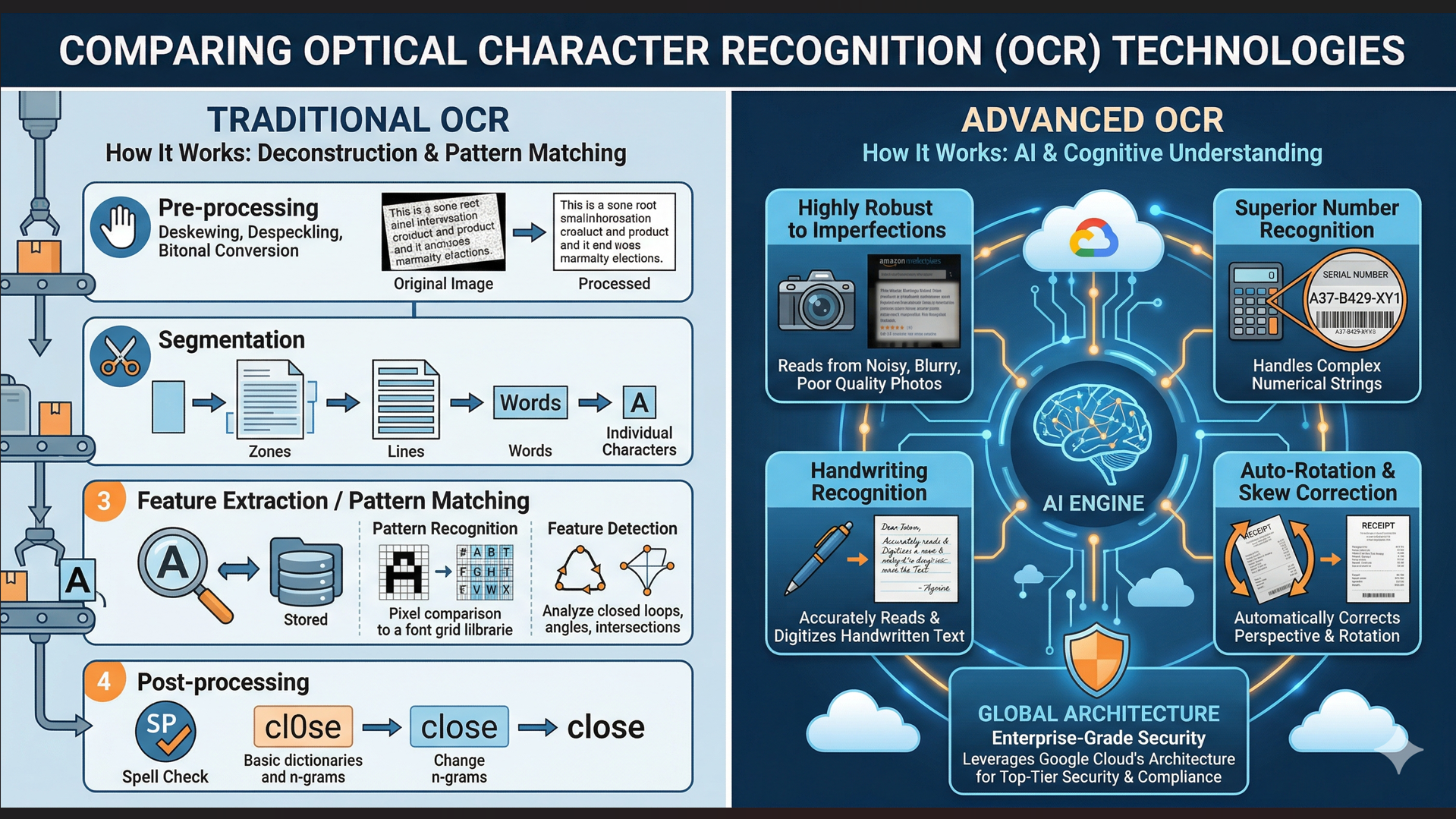
Traditional OCR doesn't just "see" a page; it deconstructs it through a series of mechanical steps:
Pre-processing: The system cleans the image to improve accuracy. This includes deskewing (straightening tilted pages), despeckling (removing digital "noise"), and converting the image to bitonal (pure black and white).
Segmentation: The software identifies the "zones" of a document. It separates images from text blocks and then breaks those blocks down into lines, words, and finally, individual characters.
Feature Extraction / Pattern Matching: This is the core engine. The software compares each isolated character against a stored library of fonts and shapes.
Pattern Recognition: Matches the character pixel-for-pixel against a known font.
Feature Detection: Looks for specific traits, like closed loops, angled lines, or intersections.
Post-processing: The system uses basic dictionaries or "n-gram" frequencies (common letter sequences) to correct likely errors—for example, changing "cl0se" to "close."
Counterfeiters often try to bypass text-based search filters (which look at titles and descriptions) by putting the brand name or a "discount" price directly inside the product image.
The Use Case: Traditional OCR scans thousands of product listing photos every minute to find "hard-coded" text like "Rolex," "Gucci," or "70% OFF" that isn't mentioned in the metadata.
Why Traditional: It is fast enough to scan the entire incoming "firehose" of new listings on sites like Amazon, Alibaba, or Instagram in real-time.
Fraudulent ads often use visual tricks to fool the human eye, such as replacing a lowercase "L" with a "1" (e.g., AppIe vs Apple).
The Use Case: Traditional OCR is used to extract text from sponsored ads and social media banners. Because it is literal and doesn't "auto-correct" like AI, it will report exactly what it sees.
The Benefit: It catches the "1" where a human might just see an "l," instantly flagging a phishing or scam site that is mimicking a brand's visual identity.
Many high-end products now include a small, standardized text block on the bottom of the box for logistics tracking.
The Use Case: When a grey market seller (someone selling genuine goods outside authorized channels) posts a photo of the box, traditional OCR can instantly read the distributor codes.
The Result: The brand can trace exactly which authorized wholesaler leaked the product to the unauthorized seller, helping to shut down "leaky" supply chains.
Many sellers on sites like Redbubble or Etsy use automated scripts to slap brand names onto t-shirts and mugs.
The Use Case: Traditional OCR acts as a "tripwire." It constantly scans new uploads for specific trademarked phrases or slogans.
Why Traditional: Since these "print on demand" fonts are usually very clean and typed, traditional OCR can achieve nearly 100% accuracy at a fraction of the cost of running a heavy AI vision model on every single t-shirt design uploaded globally.
Zeal’s Advanced OCR (Optical Character Recognition) is a powerful text extraction service built on top of the Google Cloud Vision API. It is designed to reliably "read" and digitize text from images, documents, and real-world objects.
Highly Robust to Imperfections: Unlike traditional OCR tools that require perfect, flat scans, Advanced OCR excels at reading text from noisy, blurry, or low-lighting images. This is crucial when monitoring online marketplaces, as photos taken by individual sellers are often unprofessional and of poor quality.
Superior Number Recognition: Deals significantly better with complex numerical strings (e.g., serial numbers, lot numbers).
Handwriting Recognition: Accurately reads and digitizes handwritten notes, not just printed text.
Auto-Rotation & Skew Correction: Automatically corrects the perspective of images taken at bad angles before extracting the text.
Enterprise-Grade Security: Leverages Google Cloud's architecture to ensure top-tier data security and compliance.
Advanced OCR seamlessly reads and extracts multiple languages, even when they appear in the same image. It covers a wide range of mainstream languages, including but not limited to:
English
French
German
Spanish
Chinese (Simplified & Traditional)
Japanese
Note: The detailed list of all supported languages can be found here
Counterfeiters often use "leetspeak" or symbols to bypass simple keyword filters (e.g., writing Vüitt0n or N-I-K-E).
Advanced OCR Capability: Because it uses "Visual Context," it recognizes that these characters, despite the symbols, form a protected brand name.
Brand Protection Use: It can flag listings that traditional filters miss, identifying bad actors who are intentionally trying to stay "under the radar."
Traditional OCR needs flat, straight text. If a brand name is printed on a wrinkled t-shirt, a curved perfume bottle, or a shiny watch face, traditional OCR usually fails.
Advanced OCR Capability: It uses Deep Learning to "unwarp" the text mentally. It can read a logo even if it’s angled, partially obscured by a shadow, or wrapped around a cylindrical bottle.
Brand Protection Use: This is vital for verifying the authenticity of luxury goods in "real-life" photos posted by unauthorized resellers on social media.
In the Grey Market, sellers often take legitimate invoices or shipping manifests and "wash" them—digitally altering the dates, quantities, or destination codes to hide where they got the product.
Advanced OCR Capability: It doesn't just read the text; it analyzes the forensics of the document. It can detect if the font of a "Quantity" number is slightly different from the rest of the page, or if the pixels around a "Date" suggest it was edited.
Brand Protection Use: This helps legal teams identify supply chain leaks and fraudulent distribution networks.
Sometimes a brand isn't using your name, but they are using your brand voice and slogans in their marketing images to confuse customers (e.g., a generic shoe using the phrase "Just Accomplish It").
Advanced OCR Capability: It extracts the text and passes it to an LLM (Large Language Model) to analyze the "Semantic Similarity" to your brand's protected slogans.
Brand Protection Use: It identifies "dupes" and "lookalikes" that avoid trademarked names but infringe on your brand's unique marketing identity and "Trade Dress."
Feature | Traditional OCR | Advanced (AI) OCR |
Core Logic | Pattern Matching: Matches pixels against a font template. | Neural Networks: Learns features (curves/edges) like a human brain. |
Contextual Awareness | None: Sees "0" and "O" as distinct shapes only. | High: Knows it's "2026" (numbers) not "ZOZ6" (letters). |
Layout Flexibility | Rigid: Requires "Zonal Templates" (fixed coordinates). | Dynamic: Can find a "Total" amount anywhere on a page. |
Image Quality | Sensitive: Needs clean, high-contrast scans. | Robust: Can "see through" shadows, wrinkles, or blurs. |
Speed | Extremely Fast: Low computational cost. | Moderate/Slower: Requires more processing power. |
